
본문
압축의 원리
1. 압축을 이용하는 이유
방송제작 스튜디오에서 사용하는 표준신호인 ITU-R BT 601 신호는 다음과 같은 비트래이트를 사용한다.
• Y: 8bits 720pixels X 480lines X 30frames = 83Mbps
• Cr: 8bits 360pixels X 480lines X 30frames = 42Mbps
• Cb: 8bits 360pixels X 480lines X 30frames = 42Mbps
• 합 : 167Mbps
이것은 단지 각 샘플을 8비트로 양자화 할 때의 경우이다. 만약 10비트 양자화를 적용한다면 비트래이트는 200Mbps를 능가할 것이다. 이것은 21 ~ 25Mbyte/s와 대등하다. 이런 높은 비트래이트로는 주파수 밴드가 허용하는 범위 내에서의 전송이 불가능하고 또한 저장의 측면에서 보면 저장공간과 비용의 증가로 경제적이지 못하다. 따라서 주파수밴드와 저장공간을 절약하기 위해 비디오 신호는 압축되어야만 한다.
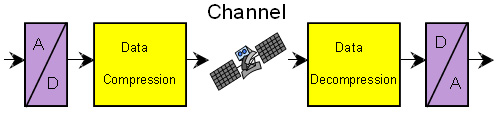
< 그림 1 압축의 목적 >
현재의 기술은 비디오 신호의 distribution(분배)을 위해 10Mbps 이하의 비트래이트로도 20:1 - 40:1 혹은 더 이상으로 데이터의 양을 줄일 수 있게 한다. 저장을 위한 비트래이트는 2:1과 5:1 사이의 Factor를 이용하여 데이터 양을 줄인다.
2. 비디오 데이터는 어떻게 압축되는가?
여기에서 키워드는 Redundancy와 Irrelevance이다. 비디오 신호는 유사한 많은 정보들을 가지고 있다. 이 중복된 정보들은 신호품질의 어떠한 손실도 없이 신호로부터 제거 될 수 있다.
또한 중복된 정보에 포함된 대부분의 신호는 인간의 눈에 감지되지 않는 많은 양의 특정 정보를 담고 있다. 이러한 정보를 제거함으로써 품질에 다소 변화가 있을 수 있지만, 만약 이것이 교묘히 수행된다면 인간의 눈은 차이를 발견하지 못 할 것이다.
■ 2.1 공간적 도메인의 중복성
비디오 프래임에서 많은 양의 데이터를 줄이기 위한 첫 단계는 비디오의 각 프래임을 개별적으로 분석하는 것이다. 즉, 프래임을 정지 화상처럼 다룬다. 이미지의 특성상 이들은 동일한 정보를 가진 수많은 픽셀들로 이루어져 있다. 이러한 특성을 이용함으로써 어떠한 품질의 희생 없이 데이터의 양을 줄이는 것이 가능하다. 집과 푸른 하늘이 있는 그림에서 푸른 하늘 부분은 유사한 루미넌스 혹은 크로마 값을 가진 많은 양의 픽셀로 구성된다. 즉 이 그림은 많은 중복성을 가지고 있다. 만약 이 픽셀들의 값이 한꺼번에 저장되거나 기억된다면 동일한 정보들이 저장에 필요한 많은 공간을 차지 할 것이다. 이러한 공간적 중복성은 제거될 수 있다.(저장을 위한 평균 factor는 2:1)
중복성 제거의 처리는 압축 알고리즘의 Run length coding과 Variable Length coding에서 수행된다. 이것을 lossless 처리라 부르며 따라서 완전하게 복원될 수 있다.
■ 2.2 Irrelevant Information (비상관적 정보)
Lossless 기술의 사용 외에, 비디오 프래임에서 데이터의 양을 줄이기 위해서는 신호로부터 특정 정보를 제거하는 것이 불가피하다. 이것을 Lossy 처리라 부르며 따라서 복원이 불가능하다. 만약 이 방법이 현명하게 수행된다면 평균적 시각으로는 감지 할 수 없는 효과를 줄 것이다. 가느다란 수직 막대로 세워진 울타리가 있는 그림을 예로 들면, 이 그림은 많은 중복적 정보를 가지고 있지 않다. 가는 수직 막대들은 고주파 신호 컴퍼넌트를 나타낸다. 이 고주파 성분을 간단히 제거하는 것은 울타리 부분의 신호 품질의 저하가 분명히 보여지기 때문에 좋은 대안이 되지 못한다. 이 시나리오에는 다른 전략이 구사되어야 한다. 인간의 눈은 세밀한 부분의 물체에서 밝기나 색의 차이를 잘 구별 할 수 없기 때문에 이 부분에서의 결함의 일정양은 감지하지 못 할 것이다. 그러므로 물체의 매우 세밀한 부분에서의 루미넌스와 크로미넌스의 레벨을 보다 거칠게(coarse) 선택 할 수 있다. 즉, 이것은 신호의 내용을 보다 적은 비트를 사용하여 표현 할 수 있음을 말한다. 따라서 이 경우 보통의 8비트 대신에 잠시동안 6비트의 사용이 가능하다.
중복성의 제거와는 달리 이 처리는 다양한 레벨의 비트래이트를 조정 할 수 있게 한다. 또한 비트래이트와 품질 사이를 가늠하는 압축 알고리즘 디벨롭퍼(developer)를 제공함으로써 광범위한 애플리캐이션의 실현을 가능하게 한다. 압축처리과정에서 비상관적 정보의 제거는 양자화(quantization)에서 처리된다.
위에 설명된 두 가지의 방법은 M-JPEG, DV과 Wavelet과 같은 현존하는 압축의 해법으로 사용되고 있다.
■ 2.3 시간 도메인의 중복성
이전의 방법들은 비디오 신호를 정지화상의 연속적 그림으로 다루었고 압축기술을 각 프래임에 개별적으로 사용하는 것이었다. 만약 시간적 도메인에서 본다면 더 많은 중복된 정보들을 발견하고 이를 제거 할 수 있다. 비디오 신호에서 연속되는 프래임에 있는 정보들은 매우 유사하며 어떤 경우는 동일하다. 이 중복적 요소는 특정 그룹의 프래임을 위해 요구되는 데이터의 양을 보다 많이 줄이는데 사용될 수 있다. 이 경우 특정 수의 프래임은 데이터 양의 감소를 얻기 위해 항상 동시에 다루어져야 한다.
프래임들 사이의 유사성을 이용한 전형적인 압축 시스템이 MPEG-2이다. MPEG-2에서 2-15프래임 사이의 GOP(group of picture)는 중복된 정보의 발견과 이 의 제거를 위해 항상 같이 분석된다. 이 절차는 기본적으로 위에서 설명한 방법을 사용하는 GOP의 첫 번째 이미지를 압축함으로써 시작된다. 즉, 이미지 내의 중복성을 제거하고 irrelevant한 내용에 reduction을 적용한다. GOP 내의 첫 번째 이미지는 Intra 혹은 I프래임이라 부른다. 그 다음, 두 번째 이미지는 이전의 것과 비교된다. 만약 현재 이미지의 비교처리가 단지 이전의 것만으로 이루어진다면, 이 프래임을 Predicted 혹은 P프래임으로 부른다. 만약 현재의 이미지가 GOP에서 이전과 이후의 둘 다의 프래임과 비교된다면 이것을 Bi-directional 혹은 B프래임이라 부른다.
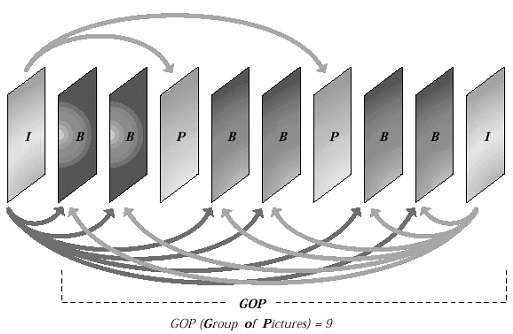
< 그림 2 MPEG-2 GOP의 I,B & P프래임 >
비교처리는 근본적으로 이전의 프래임으로부터 두 번째 프래임의 차이(픽셀-픽셀)를 감하는 것이다. 비교의 결과는 통상적인 방법으로 다루어진다. 즉 중복적요소가 제거되고 상관적 정보가 줄여진다. 만약 처리중인 두 프래임이 매우 유사하다면 처리후 데이터는 매우 작아진다. 이것이 20:1 혹은 40:1의 MPEG-2 압축비가 품질의 열화 없이 얻어지는 이유이다. 일반적으로 길이가 긴 GOP는 짧은 GOP보다 압축하는데 더 효과적이다. 그래서 MPEG-2에서 GOP는 12-15프래임의 길이로 사용된다. 이것은 신호가 비교적 적은 양의 주파수폭을 사용하면서도 고품질을 유지하면서 전송될 수 있게 한다.
메모리에서 동시에 여러 프래임을 다루는 복잡한 처리과정 때문에 긴 GOP를 사용한는 MPEG-2 인코더는 처리과정에서 큰 딜레이를 가진다. 이것은 point to point의 라이브 애플리캐이션의 사용에 다소 부적합하다. MPEG-2 인코더는 많은 처리 단계를 가지므로 많은 하드웨어가 필요하고 따라서 비싸다. 한편 디코더 측은 간단하여 비용면에서 경제적이다. 이 복잡한 인코더와 간단한 디코더의 결합을 Non-symmetrical(비대칭) 시스템이라 부른다. 반면 인코딩과 디코딩의 복잡한 정도가 동등한 시스템은 symmetrical 시스템이라 부른다. Distribution 애플리개이션을 위해서는 비대칭 시스템이 적합하다. 그것은 하나의 비싼 인코더가 값싼 여러 개의 디코더로 신호를 공급할 수 있기 때문이다. 동일한 수의 인코더와 디코더가 필요한 애플리캐이션에는 대칭 시스템이 효과적이다.
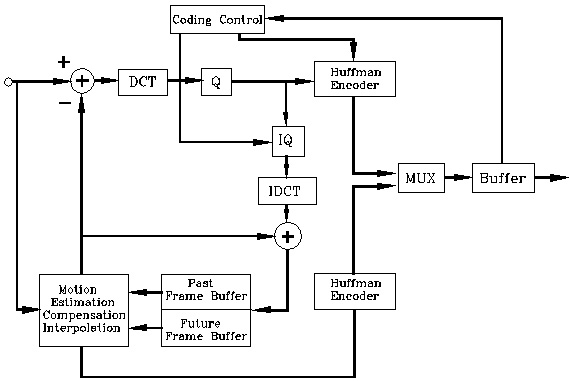
< 그림3 MPEG-2 인코더 >
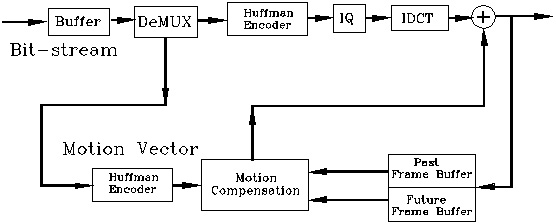
< 그림4 MPEG-2 디코더 >
3. 비디오 압축 시스템의 블록 만들기
비디오 신호의 압축을 위한 세 가지 기본적 단계가 변환(transformation), 양자화(quantization), 엔트로피 코딩(run length/VLC)이다. 처리능력을 향상하기 위해 down-sampling과 shuffling과 같은 부가적인 방법이 사용될 수 있다. 아래에서 각 단계의 목적에 대해 설명한다.
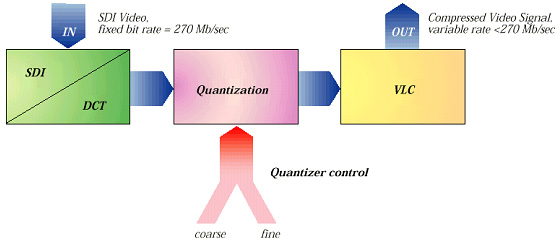
< 그림 5 압축 시스템의 기본적인 블록 만들기 >
■ 3.1 변환(DCT)
정상적인 루미넌스와 크로미넌스 신호는 압축에 보다 적합하게 만들어지기 위해 변환 과정을 거쳐야만 한다. 변환은 프래임에서 데이터의 양을 줄이는 것이 아니다. 이것은 단지 프래임이 가지고 있는 정보를 나타내는 방법을 바꾸는 것이다. 이 정보의 다른 표현은 프래임의 내용을 쉽게 분석 할 수 있게 하고 그 속에 있는 중복성과 상관적인 정보의 발견을 쉽게 한다.
< 그림 6 DCT 처리 >
만약 변환이 매우 정확한 알고리즘의 사용으로 이루어 졌다면 이는 완전한 복원이 가능하다. 즉 이 변환은 신호 품질에 어떠한 영향도 주지 않은 것이다. 보통 비디오의 압축에 사용되는 변환은 Discrete Cosine Transformation(DCT)이다. 이것은 8X8 픽셀(64픽셀)의 매트릭스로 구성된 작은 블록을 사용한다. DCT변환의 결과는 역시 8X8 매트릭스로 구성된 64개의 새로운 값들로 주어진다; 이 값들을 Coefficients(계수)라 부른다. 이 계수들은 변환이전의 8X8 블록이 가진 정보와 동일하다. 각각의 계수는 원래 8X8 매트릭스의 모든 픽셀의 값과 관계가 있다. 예를들면, 왼쪽 최고 모서리의 계수는 모든 원래의 64 픽셀의 평균값을 나타내며 이것을 DC계수라 부른다. 그 다음 오른쪽의 계수는 블록을 수직으로 반을 나누어 왼쪽의 32 픽셀의 평균값과 오른쪽 32 픽셀의 평균값을 비교한다. 비록 계수들이 서로 다른 값을 가지더라도 일반적으로 그들은 최고 왼쪽 편에서부터 최하 오른쪽으로 감소하는 값을 가질 것이다. 계수 데이터는 최고 왼쪽의 첫 번째 값(DC계수)을 읽고, 그 다음 나머지 값들을 지그-재그(zig-zag)로 최하 오른쪽 모서리의 값까지 읽음으로써 데이터스트림을 형성한다. 매트릭스의 마지막 계수의 끝에는 EOB(end of block)이 따라오는데 이것은 다음에 이어지는 계수는 새로운 매트릭스의 계수임을 나타내는 부호이다.
대부분의 경우 많은 수의 계수들은 매우 적거나 '0'이 될 것이다. 이것은 변환처리 후 바람직한 값들이다. 왜냐하면 값이 '0'인 모든 계수들은 예를들어 'o,o,o,o'이란 값으로 저장하는 대신에 '4'라는 하나의 수로 표현할 수 있기 때문이다. 이것은 원래 64 픽셀인 블록을 표현하는데 필요한 계수의 수를 줄여준다. 이 처리과정은 "Run length coding"을 설명할 때 보다 상세히 설명한다.
■ 3.2 양자화(Quantization)
고압축 factor를 얻기 위해서는 '0' 값을 가진 많은 계수들이 필요한 것이 분명해졌다. 양자화 처리의 목적은 신호로부터 상관적 정보를 제거하는 것이다.
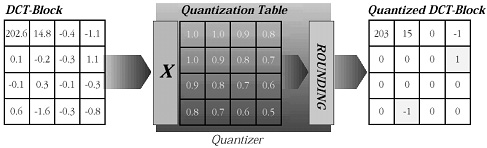
< 그림 7 양자화 과정에서의 작은 계수의 제거 >
이 상관적 정보는 보통 작은 값을 가진 계수들에 포함되어 있다. 만약 '0'에 가까운 값들이 '0'으로 대치된다면 정보의 손실은 보통 매우 적다. 이것이 양자화가 하는 역할이다. 주어진 계수들의 값을 '0'으로 대치하는 것은 복원 불가능한 처리이므로 양자화는 복원이 불가능한 Lossy 처리임이 분명하다. 이 처리는 기본적으로 division(나눔)과 라운딩(반올림/내림)이다. 64개의 계수가 있다면 64개의 나누는 수가 필요하다. 이들 나눔 factor들은 양자화 매트릭스라 불리는 또 다른 8X8의 매트릭스에 정리된다. 시스템의 복잡한 정도에 따라서 하나 이상의 양자화 매트릭스가 사용될 수 있다. 각 계수는 어떤 factor에 의해서 나누어지고 이 결과는 라운딩 된다. 만약 작은 값을 가진 어떤 계수가 충분히 큰 factor에 의해 나누어지고 나머지가 소숫점 이하이면 그 값은 당연히 '0'이 된다. 나눔 factor의 선택을 통해서 얼마나 많은 계수들의 값을 '0'으로 할 것인가를 결정할 수 있고 혹은 다른 말로 얼마나 많은 정보를 버릴 것인가를 결정 할 수 있다. DCT 매트릭스에서 각 계수는 다소 다른 값들에 의해 나누어 질 수 있기 때문에 시스템 특성 전반에 걸친 다양한 레벨의 통제가 가능하다. 압축에서 시스템이 최고 가능성 높은 나눔 매트릭스를 선택하는 것이 최상의 품질을 유지하는 핵심이다.
■ 3.3 Run length coding과 variable length coding
압축 시스템에서 중요한 마지막 단계가 런 길이와 다중 길이 코딩이다. 이것은 어디서 실제 비트래이트의 감소가 이루어지는가에 대한 것이다. 이전의 단계는 신호를 런 길이와 다중 길이 코딩을 실행하기 위한 가장 가능성 높은 형태로 바꾸는 것이었다. 런 길이와 다중 길이 코딩의 처리는 근본적으로 두 개의 다른 단계이지만 항상 같이 실행된다.
Run length coding은 양자화 후 계수의 데이터스트림을 분석하고 '0'와 같지 않은 값들을 분리하면서 연속적인 '0' 열을 찾는다. '0'와 같지 않은 값들은 바뀌지 않고 남는다. 그리고 '0'의 값들은 두 개의 '0'이 아닌 값들 사이에 있는 연속되는 '0'의 수를 나타내는 수로 대치된다. 아래의 데이터스트림을 보라.
a) Run length coding 이전:
45,0,0,0,0,62,0,0,0,0,0,0,0,0,11,0,0,9,0,0,0,0,0,0,0,0,0,0,EOB
b) Run length coding 이후:
45,4,62,8,11,2,9,EOB
데이터스트림 b)는 a)보다 아주 적은 데이터를 가지고 있음을 알 수 있다. b)에 있는 4,8과 2의 값은 a)에서 연속되는 '0'의 수를 나타낸다. 마지막 10개의 '0'는 EOB가 현재의 블록의 끝을 나타내기 때문에 전혀 표현 할 필요가 없다. 그래서 끝에 남아 있는 계수들의 값은 자동적으로 '0'으로 가정된다. 이 처리는 단지 정보를 표현하는데 이용되는 방법을 바꾸는 것이기 때문에 Lossless 처리이다. 정보 그 자체는 어떠한 방법으로도 바뀌지 않는다.
주어진 스트림에서 데이터의 양을 최소화하기 위한 다음의 단계는 다중 길이 코딩(호프만코딩)이다. 이것은 통계적 수치를 기본으로 하는 Lossless 처리이다. 어떤 데이터스트림에서 -노이즈가 아닌- 다른 것들에 비해 사용 빈도가 높은 값들이 있을 것이다. 예를 들어, 알파벳 'a'에서 'z'까지의 값을 가진 영문자를 데이터스트림으로 생각할 때, 우리는 알파벳 'e'의 사용 빈도가 'w'나 'z' 보다 훨씬 높음을 쉽게 알 수 있다. "English language"라 부르는 이 데이터스트림의 특성은 아마추어 무선에서 그들이 모오스 코드를 송신할 때 사용하는 현명한 방법이다. 모오스 코드에서 문자는 도트(dot)와 대쉬(dash)로 짧고 길게 연속되는 신호음으로 표현(코드화)된다. 각 문자는 독특한 도트와 대쉬의 형태를 가지는데, 예를 들면 문자 'z'는 "- -··"로 나타내며 문자 'e'는 "·"로 표현한다. 이것은 송신의 효율성을 높이기 위해서이다. 문자 'e'는 데이터스트림에서 자주 등장하기 때문에 짧은 부호(·)로 주어진다. 문자 'z'는 나타나는 빈도가 적으므로 보다 긴 부호(- - ··)가 주어진다. 여기서 최상의 데이터 표현 방법을 선택하기 위해서 데이터스트림에 관한 통계적인 정보의 이용이 얼마나 유용하고 또한 효율적인가를 쉽게 알 수 있다. 압축된 비디오의 데이터스트림에서도 마찬가지이다. 만약 이 값들이 통계적으로 분석되었다면, 어떤 값들의 조합이 다른 것들에 비해 보다 빈도가 높음을 나타내는 것이 가능해질 것이다. 이 특성은 자주 발생하는 값에 대해서는 짧은 이진코드를 좀처럼 발생하지 않는 값에 대해서는 긴 이진코드를 할당하는데 사용할 수 있다. 이 Run length 코딩과 가변 길이 코딩은 데이터 스트림의 분석을 필요로 하기 때문에 통상적으로 하나의 single step에서 수행된다.
■ 정리
- DCT는 압축 시스템의 Lossless 단계에 필수적이다.
- DCT는 압축 알고리즘이 아니다.
- 양자화는 신호로부터 비상관적 정보를 제거한다.
- 양자화는 복원 불가능하며, Lossy 처리이다.
- 양자화는 시스템의 비트래이트와 품질을 결정한다.
- 엔트로피코딩(Run length 코딩과 가변 길이코딩)은 비트래이트의 실제 감소를 결정한다.
- 엔트로피 코딩은 Lossless 처리이다.
- 모든 압축시스템(M-JPEG, DV, MPEG-2)은 동일한 3개의 Building 블록으로 구성된다: DCT변환, 양자화, 엔트로피 코딩
- 시간적 압축은 압축 효율은 증가시키지만 더욱 복잡하다.
4. 최상의 압축 해법
지금까지 압축 시스템은 모든 현존하는 압축 시스템에서 발견 할 수 있는 어떤 표준의 building 블록으로 구성되어 있다는 것을 알았다. 편집(editing)을 요구하는 애플리캐이션에는 어떤 제한이 부여된다. 대부분 이러한 경우 어떤 개별적 압축된 프래임으로의 직접적인 접근을 막기 때문에 시간적 압축이 사용될 수 없다. 이 딜레마의 전형적인 예가 바로 MPEG-2이다. 긴 GOP를 가지는 MPEG-2의 인코딩 처리는 많은 단계가 필요하고 디코딩 처리에 비해 더욱 복잡하다. 그것은 여러 프래임이 시간적 압축을 위해 메모리에 묶여 있어야 하기 때문이다. 이것은 distribution이 아닌 애플리캐이션에 대해서는 많은 불이익을 준다.
- GOP 구조에 의한 제한된 editing 능력
- 복잡한 인코딩 처리(비 대칭 시스템)에 의한 비용 증가
- 보다 긴 신호 처리 딜레이에 의한 라이브 애플리캐이션에서 문제 발생
따라서 시간적 압축의 사용은 주로 distribution을 위해 사용되어야 한다.
■ 4.1 비트래이트
대 부분 비디오 신호의 복잡성이 화상의 영역마다 다르기 때문에, 압축 시스템의 부하(load) 역시 화상의 복잡성에 따라 변 할 것이다. 이 결과는 품질을 변화하게 하거나 비트래이트를 변화하게 한다. 고정된 양자화 표를 가진 기본적인 압축 시스템에서 가변적 요소는 비트래이트 일 것이다.

< 그림 8 신호 변화의 복잡성 >
■ 4.2 가변 비트래이트 vs. 일정 비트래이트
압축된 신호를 사용하는 송신 혹은 저장 미디어에서, 압축 시스템은 출력단에 일정 혹은 가변 비트래이트 중 어떤 것을 제공 할 것인지 정해야 한다. 어떤 시스템에서는 가변 비트래이트가 최선일 수 있다. 이것은 시스템이 신호의 복잡성에도 불구하고 같은 레벨에서 사실상 품질을 유지 할 수 있게 한다. 이것의 단점은 광범위한 비트래이트의 변동이다. 만약 DVD나 하드디스크 같은 저장미디어에서 이런 변동은 이들 미디어에 의해 전달된 비트래이트가 요구에 맞추어 변할 수 있기 때문에 심각하지 않다. 그러나 주어진 주파수 범위를 능가하는 신호의 전송 혹은 테잎 저장은 효율적이지 못하거나 심지어는 불가능 할 것이다. 이들 시스템은 주로 고정된 일정 비트래이트로 동작한다. 만약 가변 비트래이트의 압축 신호가 테잎과 같은 미디어에 전송되었다면, 이 미디어의 주파수범위는 신호의 예상되는 최고의 비트래이트와 같아 져야만 할 것이다. 따라서 전송의 대부분 시간에 많은 bandwidth를 소비하게 된다. 왜냐하면 신호의 비트래이트가 낮아 졌을 때도 여전히 전체 bandwidth가 필요도 없이 열려 있기 때문이다.
일정 비트래이트를 요구하는 테잎과 같은 미디어의 요구를 충족하기 위해 일정 비트래이트를 제공하는 압축 시스템의 적용과 같은 부가적인 단계가 취해져야 한다.
■ 4.3 Feed back 시스템 vs. Feed forward 시스템
일찍이 설명한 디지털 비디오의 압축 시스템은 근본적으로 가변 비트래이트 출력을 가지는 시스템이다. 그러나 테잎 레코딩 그리고 다른 애플레캐이션들은 일정 비트래이트를 요구한다. 이것을 이루기 위해 압축 시스템의 양자화 부분이 압축 시스템의 출력에서 데이터의 양을 조절하는데 사용될 수 있다. 이것은 양자화가 다양하게 이루어 질 수 있다는 것을 의미한다. 높은 양자화 레벨을 사용하면 낮은 비트래이트와 vice versa를 양보해야 한다. 두 가지 기본 원칙이 양자화를 조정하는 기능을 얻어내는데 사용될 수 있다.
첫째는 smoothing 버퍼의 사용이다. 이 버퍼는 압축 시스템에서 온 데이터를 잠시 저장하는 역할을 하는 일종의 메모리이다. 데이터는 압축 시스템의 출력에서 버퍼로 공급된다. 버퍼는 저장된 데이터의 양을 계속해서 측정한다. 만약 버퍼가 가득 차게 되면 버퍼는 양자화 모드를 조정하여 높은 모드로 전환시킨다. 버퍼의 충만 레벨이 높은 입력 비트래이트를 허용할 만큼 충분히 낮아지면 버퍼는 다시 낮은 양자화 모드로 전환시키며 이것을 반복한다.
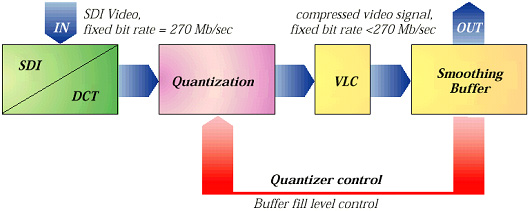
< 그림 9 Feed back을 통한 비트래이트의 조정 >
버퍼가 양자화 모드의 전환에만 의존하기 때문에 어떤 시스템이 압축 데이터스트림의 품질을 일정하게 제공하는 것은 불가능하다. 시스템은 신호의 실제 요구를 고려하지 않는다; 오직 판단 기준은 버퍼 메모리의 데이터 양이다. 이것은 신호 품질에 대단한 영향을 줄 수 있다. 더구나 일정 부분의 화상에서 얻은 신호가 다른 부분의 화상 품질에 영향을 줄 수 있다. 예를 들면 만약 화상의 상단부에 많은 양의 다루기 힘든 정보가 있다면 화상의 중간 부분도 역시 높은 양자화 모드 때문에 영향을 받을 수 있다. 이 기술은 근본적으로 Feed back 시스템이며 현존하는 다수의 압축 시스템 즉, M-JPEG와 MPEG-2에 사용된다.
두번째의 접근은 역시 양자화의 전환에 기초한 것이다. 주요 차이점은 실제 압축이 일어나기 전에 양자화 모드를 정하기 위한 최상의 가능성 있는 전략을 결정하기 위해, 그리고 바람직한 비트래이트를 얻기 위해 신호를 분석하는 것이다.
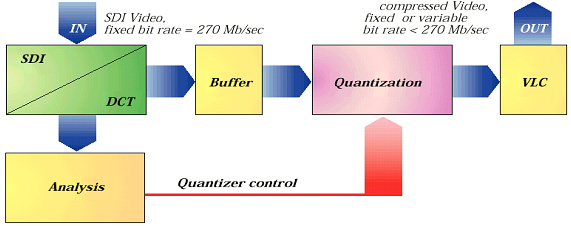
< 그림 10 Feed forward 시스템을 통한 비트래이트 조정 >
이와 같은 비트래이트를 조정하기 위한 방법은 여러 장점을 가진다. 신호의 분석이 압축 이전에 일어나기 때문에 처리되고 있는 신호의 특성에 맞는 양자화의 역동적 적용이 가능하다. 이것은 신호의 요구를 고려할 수 있게 됨으로써 품질을 더욱 일정하게 유지할 수 있게 한다. 또 다른 장점은 화상의 서로 다른 부분들 사이에 상호 영향이 발생하지 않는다는 것이다. 이것은 Feed back 시스템의 결점 없이 일정한 비트래이트로 신호를 공급한다. 신호의 분석이 실제 압축이 일어나기 전에 실시간으로 실행되어야 하기 때문에 이 기술의 처리에 필요한 전력은 다소 높다.
※ 출처 - http://www.xpert.co.kr/main/html/welcome/sdcho.html
1. 압축을 이용하는 이유
방송제작 스튜디오에서 사용하는 표준신호인 ITU-R BT 601 신호는 다음과 같은 비트래이트를 사용한다.
• Y: 8bits 720pixels X 480lines X 30frames = 83Mbps
• Cr: 8bits 360pixels X 480lines X 30frames = 42Mbps
• Cb: 8bits 360pixels X 480lines X 30frames = 42Mbps
• 합 : 167Mbps
이것은 단지 각 샘플을 8비트로 양자화 할 때의 경우이다. 만약 10비트 양자화를 적용한다면 비트래이트는 200Mbps를 능가할 것이다. 이것은 21 ~ 25Mbyte/s와 대등하다. 이런 높은 비트래이트로는 주파수 밴드가 허용하는 범위 내에서의 전송이 불가능하고 또한 저장의 측면에서 보면 저장공간과 비용의 증가로 경제적이지 못하다. 따라서 주파수밴드와 저장공간을 절약하기 위해 비디오 신호는 압축되어야만 한다.
< 그림 1 압축의 목적 >
현재의 기술은 비디오 신호의 distribution(분배)을 위해 10Mbps 이하의 비트래이트로도 20:1 - 40:1 혹은 더 이상으로 데이터의 양을 줄일 수 있게 한다. 저장을 위한 비트래이트는 2:1과 5:1 사이의 Factor를 이용하여 데이터 양을 줄인다.
2. 비디오 데이터는 어떻게 압축되는가?
여기에서 키워드는 Redundancy와 Irrelevance이다. 비디오 신호는 유사한 많은 정보들을 가지고 있다. 이 중복된 정보들은 신호품질의 어떠한 손실도 없이 신호로부터 제거 될 수 있다.
또한 중복된 정보에 포함된 대부분의 신호는 인간의 눈에 감지되지 않는 많은 양의 특정 정보를 담고 있다. 이러한 정보를 제거함으로써 품질에 다소 변화가 있을 수 있지만, 만약 이것이 교묘히 수행된다면 인간의 눈은 차이를 발견하지 못 할 것이다.
■ 2.1 공간적 도메인의 중복성
비디오 프래임에서 많은 양의 데이터를 줄이기 위한 첫 단계는 비디오의 각 프래임을 개별적으로 분석하는 것이다. 즉, 프래임을 정지 화상처럼 다룬다. 이미지의 특성상 이들은 동일한 정보를 가진 수많은 픽셀들로 이루어져 있다. 이러한 특성을 이용함으로써 어떠한 품질의 희생 없이 데이터의 양을 줄이는 것이 가능하다. 집과 푸른 하늘이 있는 그림에서 푸른 하늘 부분은 유사한 루미넌스 혹은 크로마 값을 가진 많은 양의 픽셀로 구성된다. 즉 이 그림은 많은 중복성을 가지고 있다. 만약 이 픽셀들의 값이 한꺼번에 저장되거나 기억된다면 동일한 정보들이 저장에 필요한 많은 공간을 차지 할 것이다. 이러한 공간적 중복성은 제거될 수 있다.(저장을 위한 평균 factor는 2:1)
중복성 제거의 처리는 압축 알고리즘의 Run length coding과 Variable Length coding에서 수행된다. 이것을 lossless 처리라 부르며 따라서 완전하게 복원될 수 있다.
■ 2.2 Irrelevant Information (비상관적 정보)
Lossless 기술의 사용 외에, 비디오 프래임에서 데이터의 양을 줄이기 위해서는 신호로부터 특정 정보를 제거하는 것이 불가피하다. 이것을 Lossy 처리라 부르며 따라서 복원이 불가능하다. 만약 이 방법이 현명하게 수행된다면 평균적 시각으로는 감지 할 수 없는 효과를 줄 것이다. 가느다란 수직 막대로 세워진 울타리가 있는 그림을 예로 들면, 이 그림은 많은 중복적 정보를 가지고 있지 않다. 가는 수직 막대들은 고주파 신호 컴퍼넌트를 나타낸다. 이 고주파 성분을 간단히 제거하는 것은 울타리 부분의 신호 품질의 저하가 분명히 보여지기 때문에 좋은 대안이 되지 못한다. 이 시나리오에는 다른 전략이 구사되어야 한다. 인간의 눈은 세밀한 부분의 물체에서 밝기나 색의 차이를 잘 구별 할 수 없기 때문에 이 부분에서의 결함의 일정양은 감지하지 못 할 것이다. 그러므로 물체의 매우 세밀한 부분에서의 루미넌스와 크로미넌스의 레벨을 보다 거칠게(coarse) 선택 할 수 있다. 즉, 이것은 신호의 내용을 보다 적은 비트를 사용하여 표현 할 수 있음을 말한다. 따라서 이 경우 보통의 8비트 대신에 잠시동안 6비트의 사용이 가능하다.
중복성의 제거와는 달리 이 처리는 다양한 레벨의 비트래이트를 조정 할 수 있게 한다. 또한 비트래이트와 품질 사이를 가늠하는 압축 알고리즘 디벨롭퍼(developer)를 제공함으로써 광범위한 애플리캐이션의 실현을 가능하게 한다. 압축처리과정에서 비상관적 정보의 제거는 양자화(quantization)에서 처리된다.
위에 설명된 두 가지의 방법은 M-JPEG, DV과 Wavelet과 같은 현존하는 압축의 해법으로 사용되고 있다.
■ 2.3 시간 도메인의 중복성
이전의 방법들은 비디오 신호를 정지화상의 연속적 그림으로 다루었고 압축기술을 각 프래임에 개별적으로 사용하는 것이었다. 만약 시간적 도메인에서 본다면 더 많은 중복된 정보들을 발견하고 이를 제거 할 수 있다. 비디오 신호에서 연속되는 프래임에 있는 정보들은 매우 유사하며 어떤 경우는 동일하다. 이 중복적 요소는 특정 그룹의 프래임을 위해 요구되는 데이터의 양을 보다 많이 줄이는데 사용될 수 있다. 이 경우 특정 수의 프래임은 데이터 양의 감소를 얻기 위해 항상 동시에 다루어져야 한다.
프래임들 사이의 유사성을 이용한 전형적인 압축 시스템이 MPEG-2이다. MPEG-2에서 2-15프래임 사이의 GOP(group of picture)는 중복된 정보의 발견과 이 의 제거를 위해 항상 같이 분석된다. 이 절차는 기본적으로 위에서 설명한 방법을 사용하는 GOP의 첫 번째 이미지를 압축함으로써 시작된다. 즉, 이미지 내의 중복성을 제거하고 irrelevant한 내용에 reduction을 적용한다. GOP 내의 첫 번째 이미지는 Intra 혹은 I프래임이라 부른다. 그 다음, 두 번째 이미지는 이전의 것과 비교된다. 만약 현재 이미지의 비교처리가 단지 이전의 것만으로 이루어진다면, 이 프래임을 Predicted 혹은 P프래임으로 부른다. 만약 현재의 이미지가 GOP에서 이전과 이후의 둘 다의 프래임과 비교된다면 이것을 Bi-directional 혹은 B프래임이라 부른다.
< 그림 2 MPEG-2 GOP의 I,B & P프래임 >
비교처리는 근본적으로 이전의 프래임으로부터 두 번째 프래임의 차이(픽셀-픽셀)를 감하는 것이다. 비교의 결과는 통상적인 방법으로 다루어진다. 즉 중복적요소가 제거되고 상관적 정보가 줄여진다. 만약 처리중인 두 프래임이 매우 유사하다면 처리후 데이터는 매우 작아진다. 이것이 20:1 혹은 40:1의 MPEG-2 압축비가 품질의 열화 없이 얻어지는 이유이다. 일반적으로 길이가 긴 GOP는 짧은 GOP보다 압축하는데 더 효과적이다. 그래서 MPEG-2에서 GOP는 12-15프래임의 길이로 사용된다. 이것은 신호가 비교적 적은 양의 주파수폭을 사용하면서도 고품질을 유지하면서 전송될 수 있게 한다.
메모리에서 동시에 여러 프래임을 다루는 복잡한 처리과정 때문에 긴 GOP를 사용한는 MPEG-2 인코더는 처리과정에서 큰 딜레이를 가진다. 이것은 point to point의 라이브 애플리캐이션의 사용에 다소 부적합하다. MPEG-2 인코더는 많은 처리 단계를 가지므로 많은 하드웨어가 필요하고 따라서 비싸다. 한편 디코더 측은 간단하여 비용면에서 경제적이다. 이 복잡한 인코더와 간단한 디코더의 결합을 Non-symmetrical(비대칭) 시스템이라 부른다. 반면 인코딩과 디코딩의 복잡한 정도가 동등한 시스템은 symmetrical 시스템이라 부른다. Distribution 애플리개이션을 위해서는 비대칭 시스템이 적합하다. 그것은 하나의 비싼 인코더가 값싼 여러 개의 디코더로 신호를 공급할 수 있기 때문이다. 동일한 수의 인코더와 디코더가 필요한 애플리캐이션에는 대칭 시스템이 효과적이다.
< 그림3 MPEG-2 인코더 >
< 그림4 MPEG-2 디코더 >
3. 비디오 압축 시스템의 블록 만들기
비디오 신호의 압축을 위한 세 가지 기본적 단계가 변환(transformation), 양자화(quantization), 엔트로피 코딩(run length/VLC)이다. 처리능력을 향상하기 위해 down-sampling과 shuffling과 같은 부가적인 방법이 사용될 수 있다. 아래에서 각 단계의 목적에 대해 설명한다.
< 그림 5 압축 시스템의 기본적인 블록 만들기 >
■ 3.1 변환(DCT)
정상적인 루미넌스와 크로미넌스 신호는 압축에 보다 적합하게 만들어지기 위해 변환 과정을 거쳐야만 한다. 변환은 프래임에서 데이터의 양을 줄이는 것이 아니다. 이것은 단지 프래임이 가지고 있는 정보를 나타내는 방법을 바꾸는 것이다. 이 정보의 다른 표현은 프래임의 내용을 쉽게 분석 할 수 있게 하고 그 속에 있는 중복성과 상관적인 정보의 발견을 쉽게 한다.
< 그림 6 DCT 처리 >
만약 변환이 매우 정확한 알고리즘의 사용으로 이루어 졌다면 이는 완전한 복원이 가능하다. 즉 이 변환은 신호 품질에 어떠한 영향도 주지 않은 것이다. 보통 비디오의 압축에 사용되는 변환은 Discrete Cosine Transformation(DCT)이다. 이것은 8X8 픽셀(64픽셀)의 매트릭스로 구성된 작은 블록을 사용한다. DCT변환의 결과는 역시 8X8 매트릭스로 구성된 64개의 새로운 값들로 주어진다; 이 값들을 Coefficients(계수)라 부른다. 이 계수들은 변환이전의 8X8 블록이 가진 정보와 동일하다. 각각의 계수는 원래 8X8 매트릭스의 모든 픽셀의 값과 관계가 있다. 예를들면, 왼쪽 최고 모서리의 계수는 모든 원래의 64 픽셀의 평균값을 나타내며 이것을 DC계수라 부른다. 그 다음 오른쪽의 계수는 블록을 수직으로 반을 나누어 왼쪽의 32 픽셀의 평균값과 오른쪽 32 픽셀의 평균값을 비교한다. 비록 계수들이 서로 다른 값을 가지더라도 일반적으로 그들은 최고 왼쪽 편에서부터 최하 오른쪽으로 감소하는 값을 가질 것이다. 계수 데이터는 최고 왼쪽의 첫 번째 값(DC계수)을 읽고, 그 다음 나머지 값들을 지그-재그(zig-zag)로 최하 오른쪽 모서리의 값까지 읽음으로써 데이터스트림을 형성한다. 매트릭스의 마지막 계수의 끝에는 EOB(end of block)이 따라오는데 이것은 다음에 이어지는 계수는 새로운 매트릭스의 계수임을 나타내는 부호이다.
대부분의 경우 많은 수의 계수들은 매우 적거나 '0'이 될 것이다. 이것은 변환처리 후 바람직한 값들이다. 왜냐하면 값이 '0'인 모든 계수들은 예를들어 'o,o,o,o'이란 값으로 저장하는 대신에 '4'라는 하나의 수로 표현할 수 있기 때문이다. 이것은 원래 64 픽셀인 블록을 표현하는데 필요한 계수의 수를 줄여준다. 이 처리과정은 "Run length coding"을 설명할 때 보다 상세히 설명한다.
■ 3.2 양자화(Quantization)
고압축 factor를 얻기 위해서는 '0' 값을 가진 많은 계수들이 필요한 것이 분명해졌다. 양자화 처리의 목적은 신호로부터 상관적 정보를 제거하는 것이다.
< 그림 7 양자화 과정에서의 작은 계수의 제거 >
이 상관적 정보는 보통 작은 값을 가진 계수들에 포함되어 있다. 만약 '0'에 가까운 값들이 '0'으로 대치된다면 정보의 손실은 보통 매우 적다. 이것이 양자화가 하는 역할이다. 주어진 계수들의 값을 '0'으로 대치하는 것은 복원 불가능한 처리이므로 양자화는 복원이 불가능한 Lossy 처리임이 분명하다. 이 처리는 기본적으로 division(나눔)과 라운딩(반올림/내림)이다. 64개의 계수가 있다면 64개의 나누는 수가 필요하다. 이들 나눔 factor들은 양자화 매트릭스라 불리는 또 다른 8X8의 매트릭스에 정리된다. 시스템의 복잡한 정도에 따라서 하나 이상의 양자화 매트릭스가 사용될 수 있다. 각 계수는 어떤 factor에 의해서 나누어지고 이 결과는 라운딩 된다. 만약 작은 값을 가진 어떤 계수가 충분히 큰 factor에 의해 나누어지고 나머지가 소숫점 이하이면 그 값은 당연히 '0'이 된다. 나눔 factor의 선택을 통해서 얼마나 많은 계수들의 값을 '0'으로 할 것인가를 결정할 수 있고 혹은 다른 말로 얼마나 많은 정보를 버릴 것인가를 결정 할 수 있다. DCT 매트릭스에서 각 계수는 다소 다른 값들에 의해 나누어 질 수 있기 때문에 시스템 특성 전반에 걸친 다양한 레벨의 통제가 가능하다. 압축에서 시스템이 최고 가능성 높은 나눔 매트릭스를 선택하는 것이 최상의 품질을 유지하는 핵심이다.
■ 3.3 Run length coding과 variable length coding
압축 시스템에서 중요한 마지막 단계가 런 길이와 다중 길이 코딩이다. 이것은 어디서 실제 비트래이트의 감소가 이루어지는가에 대한 것이다. 이전의 단계는 신호를 런 길이와 다중 길이 코딩을 실행하기 위한 가장 가능성 높은 형태로 바꾸는 것이었다. 런 길이와 다중 길이 코딩의 처리는 근본적으로 두 개의 다른 단계이지만 항상 같이 실행된다.
Run length coding은 양자화 후 계수의 데이터스트림을 분석하고 '0'와 같지 않은 값들을 분리하면서 연속적인 '0' 열을 찾는다. '0'와 같지 않은 값들은 바뀌지 않고 남는다. 그리고 '0'의 값들은 두 개의 '0'이 아닌 값들 사이에 있는 연속되는 '0'의 수를 나타내는 수로 대치된다. 아래의 데이터스트림을 보라.
a) Run length coding 이전:
45,0,0,0,0,62,0,0,0,0,0,0,0,0,11,0,0,9,0,0,0,0,0,0,0,0,0,0,EOB
b) Run length coding 이후:
45,4,62,8,11,2,9,EOB
데이터스트림 b)는 a)보다 아주 적은 데이터를 가지고 있음을 알 수 있다. b)에 있는 4,8과 2의 값은 a)에서 연속되는 '0'의 수를 나타낸다. 마지막 10개의 '0'는 EOB가 현재의 블록의 끝을 나타내기 때문에 전혀 표현 할 필요가 없다. 그래서 끝에 남아 있는 계수들의 값은 자동적으로 '0'으로 가정된다. 이 처리는 단지 정보를 표현하는데 이용되는 방법을 바꾸는 것이기 때문에 Lossless 처리이다. 정보 그 자체는 어떠한 방법으로도 바뀌지 않는다.
주어진 스트림에서 데이터의 양을 최소화하기 위한 다음의 단계는 다중 길이 코딩(호프만코딩)이다. 이것은 통계적 수치를 기본으로 하는 Lossless 처리이다. 어떤 데이터스트림에서 -노이즈가 아닌- 다른 것들에 비해 사용 빈도가 높은 값들이 있을 것이다. 예를 들어, 알파벳 'a'에서 'z'까지의 값을 가진 영문자를 데이터스트림으로 생각할 때, 우리는 알파벳 'e'의 사용 빈도가 'w'나 'z' 보다 훨씬 높음을 쉽게 알 수 있다. "English language"라 부르는 이 데이터스트림의 특성은 아마추어 무선에서 그들이 모오스 코드를 송신할 때 사용하는 현명한 방법이다. 모오스 코드에서 문자는 도트(dot)와 대쉬(dash)로 짧고 길게 연속되는 신호음으로 표현(코드화)된다. 각 문자는 독특한 도트와 대쉬의 형태를 가지는데, 예를 들면 문자 'z'는 "- -··"로 나타내며 문자 'e'는 "·"로 표현한다. 이것은 송신의 효율성을 높이기 위해서이다. 문자 'e'는 데이터스트림에서 자주 등장하기 때문에 짧은 부호(·)로 주어진다. 문자 'z'는 나타나는 빈도가 적으므로 보다 긴 부호(- - ··)가 주어진다. 여기서 최상의 데이터 표현 방법을 선택하기 위해서 데이터스트림에 관한 통계적인 정보의 이용이 얼마나 유용하고 또한 효율적인가를 쉽게 알 수 있다. 압축된 비디오의 데이터스트림에서도 마찬가지이다. 만약 이 값들이 통계적으로 분석되었다면, 어떤 값들의 조합이 다른 것들에 비해 보다 빈도가 높음을 나타내는 것이 가능해질 것이다. 이 특성은 자주 발생하는 값에 대해서는 짧은 이진코드를 좀처럼 발생하지 않는 값에 대해서는 긴 이진코드를 할당하는데 사용할 수 있다. 이 Run length 코딩과 가변 길이 코딩은 데이터 스트림의 분석을 필요로 하기 때문에 통상적으로 하나의 single step에서 수행된다.
■ 정리
- DCT는 압축 시스템의 Lossless 단계에 필수적이다.
- DCT는 압축 알고리즘이 아니다.
- 양자화는 신호로부터 비상관적 정보를 제거한다.
- 양자화는 복원 불가능하며, Lossy 처리이다.
- 양자화는 시스템의 비트래이트와 품질을 결정한다.
- 엔트로피코딩(Run length 코딩과 가변 길이코딩)은 비트래이트의 실제 감소를 결정한다.
- 엔트로피 코딩은 Lossless 처리이다.
- 모든 압축시스템(M-JPEG, DV, MPEG-2)은 동일한 3개의 Building 블록으로 구성된다: DCT변환, 양자화, 엔트로피 코딩
- 시간적 압축은 압축 효율은 증가시키지만 더욱 복잡하다.
4. 최상의 압축 해법
지금까지 압축 시스템은 모든 현존하는 압축 시스템에서 발견 할 수 있는 어떤 표준의 building 블록으로 구성되어 있다는 것을 알았다. 편집(editing)을 요구하는 애플리캐이션에는 어떤 제한이 부여된다. 대부분 이러한 경우 어떤 개별적 압축된 프래임으로의 직접적인 접근을 막기 때문에 시간적 압축이 사용될 수 없다. 이 딜레마의 전형적인 예가 바로 MPEG-2이다. 긴 GOP를 가지는 MPEG-2의 인코딩 처리는 많은 단계가 필요하고 디코딩 처리에 비해 더욱 복잡하다. 그것은 여러 프래임이 시간적 압축을 위해 메모리에 묶여 있어야 하기 때문이다. 이것은 distribution이 아닌 애플리캐이션에 대해서는 많은 불이익을 준다.
- GOP 구조에 의한 제한된 editing 능력
- 복잡한 인코딩 처리(비 대칭 시스템)에 의한 비용 증가
- 보다 긴 신호 처리 딜레이에 의한 라이브 애플리캐이션에서 문제 발생
따라서 시간적 압축의 사용은 주로 distribution을 위해 사용되어야 한다.
■ 4.1 비트래이트
대 부분 비디오 신호의 복잡성이 화상의 영역마다 다르기 때문에, 압축 시스템의 부하(load) 역시 화상의 복잡성에 따라 변 할 것이다. 이 결과는 품질을 변화하게 하거나 비트래이트를 변화하게 한다. 고정된 양자화 표를 가진 기본적인 압축 시스템에서 가변적 요소는 비트래이트 일 것이다.
< 그림 8 신호 변화의 복잡성 >
■ 4.2 가변 비트래이트 vs. 일정 비트래이트
압축된 신호를 사용하는 송신 혹은 저장 미디어에서, 압축 시스템은 출력단에 일정 혹은 가변 비트래이트 중 어떤 것을 제공 할 것인지 정해야 한다. 어떤 시스템에서는 가변 비트래이트가 최선일 수 있다. 이것은 시스템이 신호의 복잡성에도 불구하고 같은 레벨에서 사실상 품질을 유지 할 수 있게 한다. 이것의 단점은 광범위한 비트래이트의 변동이다. 만약 DVD나 하드디스크 같은 저장미디어에서 이런 변동은 이들 미디어에 의해 전달된 비트래이트가 요구에 맞추어 변할 수 있기 때문에 심각하지 않다. 그러나 주어진 주파수 범위를 능가하는 신호의 전송 혹은 테잎 저장은 효율적이지 못하거나 심지어는 불가능 할 것이다. 이들 시스템은 주로 고정된 일정 비트래이트로 동작한다. 만약 가변 비트래이트의 압축 신호가 테잎과 같은 미디어에 전송되었다면, 이 미디어의 주파수범위는 신호의 예상되는 최고의 비트래이트와 같아 져야만 할 것이다. 따라서 전송의 대부분 시간에 많은 bandwidth를 소비하게 된다. 왜냐하면 신호의 비트래이트가 낮아 졌을 때도 여전히 전체 bandwidth가 필요도 없이 열려 있기 때문이다.
일정 비트래이트를 요구하는 테잎과 같은 미디어의 요구를 충족하기 위해 일정 비트래이트를 제공하는 압축 시스템의 적용과 같은 부가적인 단계가 취해져야 한다.
■ 4.3 Feed back 시스템 vs. Feed forward 시스템
일찍이 설명한 디지털 비디오의 압축 시스템은 근본적으로 가변 비트래이트 출력을 가지는 시스템이다. 그러나 테잎 레코딩 그리고 다른 애플레캐이션들은 일정 비트래이트를 요구한다. 이것을 이루기 위해 압축 시스템의 양자화 부분이 압축 시스템의 출력에서 데이터의 양을 조절하는데 사용될 수 있다. 이것은 양자화가 다양하게 이루어 질 수 있다는 것을 의미한다. 높은 양자화 레벨을 사용하면 낮은 비트래이트와 vice versa를 양보해야 한다. 두 가지 기본 원칙이 양자화를 조정하는 기능을 얻어내는데 사용될 수 있다.
첫째는 smoothing 버퍼의 사용이다. 이 버퍼는 압축 시스템에서 온 데이터를 잠시 저장하는 역할을 하는 일종의 메모리이다. 데이터는 압축 시스템의 출력에서 버퍼로 공급된다. 버퍼는 저장된 데이터의 양을 계속해서 측정한다. 만약 버퍼가 가득 차게 되면 버퍼는 양자화 모드를 조정하여 높은 모드로 전환시킨다. 버퍼의 충만 레벨이 높은 입력 비트래이트를 허용할 만큼 충분히 낮아지면 버퍼는 다시 낮은 양자화 모드로 전환시키며 이것을 반복한다.
< 그림 9 Feed back을 통한 비트래이트의 조정 >
버퍼가 양자화 모드의 전환에만 의존하기 때문에 어떤 시스템이 압축 데이터스트림의 품질을 일정하게 제공하는 것은 불가능하다. 시스템은 신호의 실제 요구를 고려하지 않는다; 오직 판단 기준은 버퍼 메모리의 데이터 양이다. 이것은 신호 품질에 대단한 영향을 줄 수 있다. 더구나 일정 부분의 화상에서 얻은 신호가 다른 부분의 화상 품질에 영향을 줄 수 있다. 예를 들면 만약 화상의 상단부에 많은 양의 다루기 힘든 정보가 있다면 화상의 중간 부분도 역시 높은 양자화 모드 때문에 영향을 받을 수 있다. 이 기술은 근본적으로 Feed back 시스템이며 현존하는 다수의 압축 시스템 즉, M-JPEG와 MPEG-2에 사용된다.
두번째의 접근은 역시 양자화의 전환에 기초한 것이다. 주요 차이점은 실제 압축이 일어나기 전에 양자화 모드를 정하기 위한 최상의 가능성 있는 전략을 결정하기 위해, 그리고 바람직한 비트래이트를 얻기 위해 신호를 분석하는 것이다.
< 그림 10 Feed forward 시스템을 통한 비트래이트 조정 >
이와 같은 비트래이트를 조정하기 위한 방법은 여러 장점을 가진다. 신호의 분석이 압축 이전에 일어나기 때문에 처리되고 있는 신호의 특성에 맞는 양자화의 역동적 적용이 가능하다. 이것은 신호의 요구를 고려할 수 있게 됨으로써 품질을 더욱 일정하게 유지할 수 있게 한다. 또 다른 장점은 화상의 서로 다른 부분들 사이에 상호 영향이 발생하지 않는다는 것이다. 이것은 Feed back 시스템의 결점 없이 일정한 비트래이트로 신호를 공급한다. 신호의 분석이 실제 압축이 일어나기 전에 실시간으로 실행되어야 하기 때문에 이 기술의 처리에 필요한 전력은 다소 높다.
※ 출처 - http://www.xpert.co.kr/main/html/welcome/sdcho.html
추천 0